
Article de Tek sous licence CC-BY-SA traduit par l’association à l’aide de DeepL.
Nous traduisons ici un guide d’OSINT (Open Source INTelligence) paru sur randhome.io afin d’aider les activistes à obtenir des informations sur, par exemple, des organisations d’extrême-droite afin de se protéger de leurs attaques. Les informations obtenues grâce à l’OSINT sont par définition accessibles publiquement. Évidemment, nous n’encourageons aucun usage illégal de ces techniques.
Par ailleurs, ce guide a été écrit pour des personnes avec un niveau déjà intermédiaire ou avancé en connaissances techniques. Si vous n’avez pas ces connaissances, vous pouvez toujours survoler l’article et l’utiliser comme une référence pour connaître les principaux outils intéressants, et voir ce que vous arriverez à en tirer. En particulier, ne sont pas abordées en profondeur les précautions nécessaires à l’investigation et à la protection de son identité et de son ordinateur sur Internet. Un bon début dans la matière est ce guide produit par Motherboard. Ne sont pas abordés non plus : l’usage d’utilitaires Linux/MacOS en ligne de commande (on pourra consulter le tutoriel d’OpenClassrooms sur le sujet), l’utilisation d’un VPS, d’un VPN, la programmation en Python…
J’ai fait beaucoup d’Intelligence Open-Source (OSINT) dernièrement, donc pour célébrer 2019, j’ai décidé de résumer beaucoup de trucs et astuces que j’ai appris dans ce guide. Bien sûr, ce n’est pas le guide parfait (aucun guide ne l’est), mais j’espère qu’il aidera les débutant-es à apprendre, et les hackers expérimenté-es d’OSINT à découvrir de nouveaux trucs.
Méthodologie
La méthodologie classique d’OSINT que vous trouverez partout est directe :
- Définir les besoins : que cherche-t-on ?
- Récupérer les données
- Analyser l’information recueillie
- Pivotement et rapport : soit définir de nouvelles exigences en s’appuyant sur les données qui viennent d’être recueillies, soit mettre fin à l’enquête et rédiger le rapport
Cette méthodologie est assez intuitive et peut ne pas aider beaucoup de gens, mais je pense qu’il est quand même important d’y revenir régulièrement, et de prendre le temps de repasser en revue les différentes étapes. Très souvent, au cours des enquêtes, nous nous perdons dans la quantité de données recueillies, et il est difficile d’avoir une idée de la direction que doit prendre l’enquête. Dans ce cas, je pense qu’il est utile de faire une pause et de revenir aux étapes 3 et 4 : analyser et résumer ce que vous avez trouvé, énumérer ce qui pourrait vous aider à pivoter et définir de nouvelles questions (ou des questions plus précises) qui nécessitent encore des réponses.

Les autres conseils que je donnerais sont :
- N’abandonnez jamais : il y aura un moment où vous aurez l’impression d’avoir exploré toutes les possibilités d’obtenir de l’information. N’abandonnez pas. Faites une pause (une heure ou une journée à faire autre chose), puis analysez à nouveau vos données et essayez de les voir sous un autre angle. Y a-t-il une nouvelle information sur laquelle vous pourriez pivoter ? Et si vous vous étiez posé-e les mauvaises questions au début ? Justin Seitz a récemment écrit un article sur la ténacité sur son blog, donnant quelques exemples où la ténacité a porté ses fruits.
- Conserver les preuves : l’information en ligne disparaît très rapidement. Imaginez que vous fassiez une seule erreur d’exécution, comme liker un tweet, ou que la personne que vous recherchiez commence à être suspicieuse, soudainement tous les comptes de réseaux sociaux et et sites Web peuvent disparaître d’un jour à l’autre. Conservez donc des preuves : captures d’écran, archives, archives web (plus d’informations sur ça plus tard) ou tout ce qui fonctionne pour vous.
- Les frises chronologiques ont du bon : en criminalistique, les délais et le fait de pivoter sur des événements qui se produisent en même temps sont essentiels. Ce n’est certainement pas aussi important dans l’OSINT mais c’est quand même un outil très intéressant pour organiser vos données. Quand le site Web a-t-il été créé ? Quand le compte Facebook a-t-il été créé ? Quand le dernier billet du blog a-t-il été publié ? Avoir tout cela dans un tableau me donne souvent une bonne vue d’ensemble de ce que je cherche.
Il y a deux autres méthodes que je trouve utiles. La première, ce sont des graphes pour décrire les méthodes de recherche d’informations en fonction d’un type de données (comme un e-mail). Le meilleur graphe que j’ai vu est celui fait par Michael Bazzell chez IntelTechniques.com. Par exemple, voici le graphe de Michael Bazzell lors de la recherche d’informations sur une adresse e-mail :
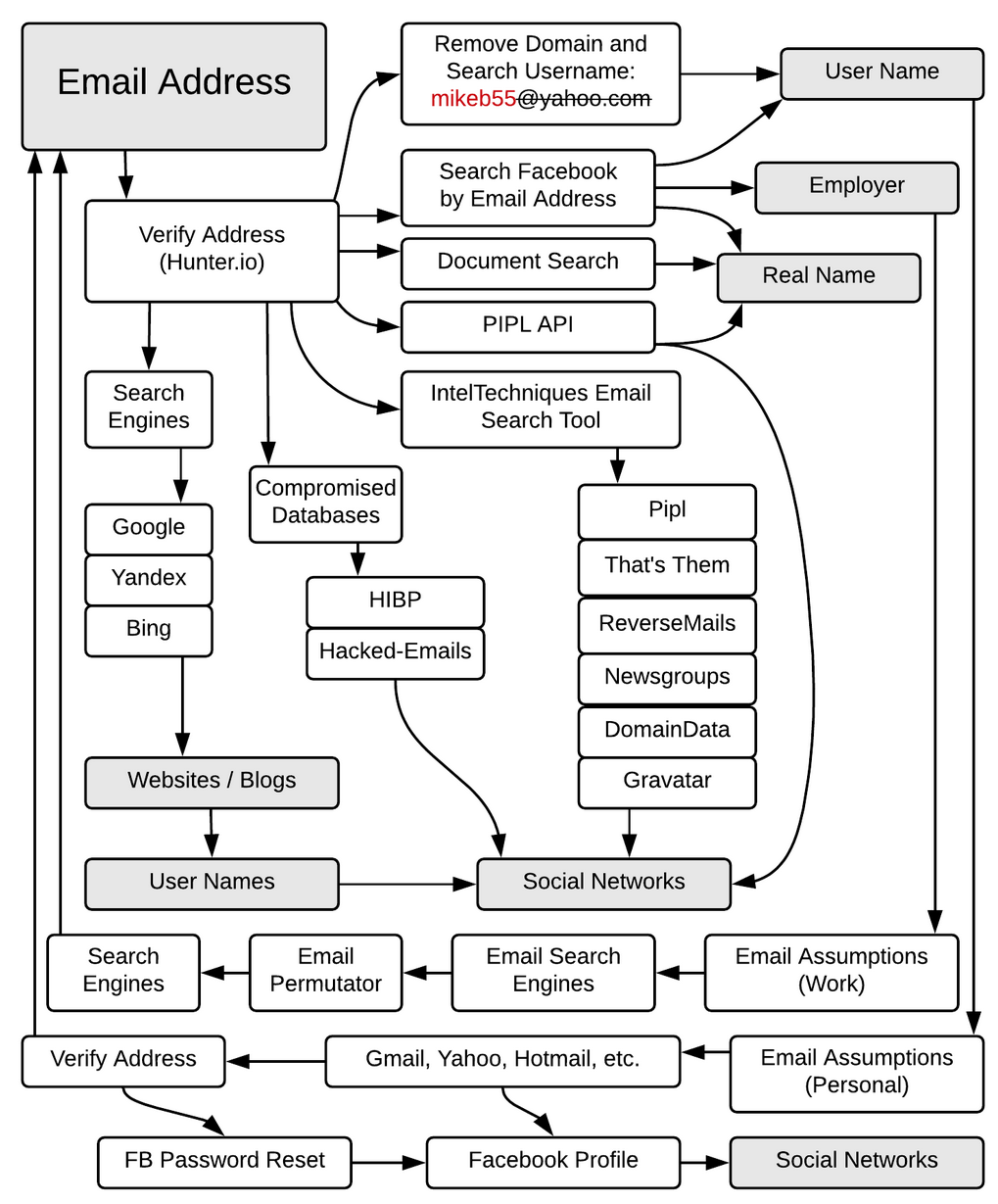
Après un certain temps, je pense que c’est une bonne idée de commencer à développer vos propres graphes d’enquête et de les améliorer lentement au fil du temps avec les nouveaux trucs que vous trouvez.
La dernière méthodologie que je recommande pour les longues enquêtes est l’analyse des hypothèses concurrentes. Cette méthodologie a été développée par la CIA dans les années 70 pour aider les analystes à éliminer les biais de leur analyse et à évaluer soigneusement les différentes hypothèses. N’oubliez pas qu’il s’agit d’un outil lourd et chronophage, mais si vous vous perdez dans une enquête qui dure un an, il est parfois bon d’avoir un processus qui vous aide à évaluer soigneusement vos hypothèses.
Préparer votre système
Avant de vous lancer dans l’enquête, il y a quelques aspects de la sécurité opérationnelle que vous devriez prendre en considération afin d’éviter d’alerter les personnes sur lesquelles vous effectuez des recherches. Visiter un site Web personnel obscur pourrait donner votre adresse IP et donc votre emplacement à votre cible, l’utilisation de votre compte personnel de réseaux sociaux pourrait conduire à un clic sur un like par erreur, etc.
Je suis les règles suivantes pendant mes investigations :
- Utilisez un VPN commercial ou Tor pour toutes les connexions depuis votre navigateur pour l’investigation. La plupart des VPN commerciaux fournissent des serveurs dans différents pays et Tor vous permet de choisir le pays du nœud de sortie donc j’essaie de choisir un pays qui n’alerterait pas en fonction du contexte (Etats-Unis pour une enquête sur une organisation américaine, etc.).
- Effectuez tous les scans et les tâches d’exploration à partir d’un VPS bon marché qui n’a aucune info sur vous.
- Utilisez des comptes de réseaux sociaux dédiés à l’enquête et créés sous un faux nom.
Après avoir fait tout cela, vous pouvez maintenant enquêter aussi tard dans la nuit que vous le souhaitez, il est assez peu probable que les gens seront en mesure d’identifier qui est à leur recherche.
Outillage
La question de l’outil est toujours une question curieuse dans l’infosec, rien ne me dérange plus que les gens qui listent une liste interminable d’outils dans leur CV et non les compétences qu’ils ont. Permettez-moi donc de le dire clairement : les outils n’ont pas d’importance, c’est ce que vous faites avec les outils qui comptent. Si vous ne savez pas ce que vous faites, les outils ne vous aideront pas, ils vous donneront simplement une longue liste de données que vous ne pourrez pas comprendre ou évaluer. Testez les outils, lisez leur code, créez vos propres outils, etc, mais assurez-vous de bien comprendre ce qu’ils font.
Le corollaire, c’est qu’il n’y a pas de boîte à outils parfaite. La meilleure boîte à outils est celle que vous connaissez, aimez et maîtrisez. Mais laissez-moi vous dire ce que j’utilise et quels autres outils peuvent vous intéresser.
Chrome et les modules
J’utilise Chrome comme navigateur d’investigation, principalement parce que Hunchly n’est disponible que pour Chrome (voir ci-dessous). J’y ajoute quelques plugins utiles :
- archive.is Button permet d’enregistrer rapidement une page web dans archive.is (plus d’informations à ce sujet plus tard)
- Wayback Machine pour rechercher une page archivée dans archive.org Wayback machine
- OpenSource Intelligence donne un accès rapide à de nombreux outils OSINT
- EXIF Viewer permet de visualiser rapidement les données EXIF en images
- FireShot pour faire des captures d’écran rapidement
Hunchly
J’ai récemment commencé à utiliser Hunchly et c’est un excellent outil. Hunchly est une extension Chrome qui permet de sauvegarder, étiqueter et rechercher toutes les données web que vous trouvez pendant l’enquête. Fondamentalement, il vous suffit de cliquer sur « Capture » dans l’extension lorsque vous démarrez une enquête, et Hunchly enregistrera toutes les pages web que vous visitez dans une base de données, vous permettant d’y ajouter des notes et des tags.
Il coûte 130$/an, ce qui n’est pas grand-chose si l’on considère son utilité.
Maltego
Maltego est plus un outil de threat intelligence qu’un outil OSINT et a de nombreuses limites, mais un graphe est souvent le meilleur moyen de représenter et d’analyser les données d’enquête et Maltego est bon à ça. Fondamentalement Maltego offre une interface graphique pour créer des graphes, et d’enrichir le graphe avec de nouvelles données (par exemple, des domaines liés à une adresse IP d’une base de données « passive DNS »). C’est un peu cher (999$/an la première année, puis 499$/an pour le renouvellement) et ne vaut peut-être la peine que si vous faites aussi du threat intel ou beaucoup d’analyse des infrastructures. Vous pouvez également utiliser Maltego Community Edition qui limite l’utilisation de l’option transform et la taille du graphique, mais elle devrait être largement suffisante pour les petites enquêtes.
Harpoon
J’ai développé un outil en ligne de commande appelé Harpoon (voir le billet de blog ici pour plus de détails). Il a commencé comme un outil de threat intel, mais j’ai ajouté de nombreuses commandes pour l’OSINT. Il fonctionne avec python3 sous Linux (mais MacOS et Windows devraient aussi fonctionner) et est open source.
Par exemple, vous pouvez utiliser Harpoon pour rechercher une clé PGP sur des serveurs de clés :
$ harpoon pgp search tek@randhome.io
[+] 0xDCB55433A1EA7CAB 2016-05-30 Tek__ tek@randhome.ioIl y a une longue liste de plugins, n’hésitez pas à coder de nouvelles fonctionnalités intéressantes ou à suggérer des améliorations.
Python
Très souvent, vous vous retrouverez avec des tâches spécifiques de collecte et de visualisation de données qui ne peuvent pas être effectuées facilement avec n’importe quel outil. Dans ce cas, vous devrez écrire votre propre code. J’utilise python pour cela, n’importe quel langage de programmation moderne fonctionnerait également, mais j’aime la flexibilité de python et le nombre énorme de bibliothèques disponibles.
Justin Seitz (l’auteur de Hunchly) est une référence sur python et l’OSINT, et vous devriez certainement jeter un œil à son blog Automating OSINT et son livre Black Hat Python.
Vous aimerez peut-être aussi…
Il existe bien sûr de nombreux autres outils pour l’OSINT, mais je les trouve moins utiles dans mon travail quotidien. Voici quelques outils que vous voudrez peut-être regarder, ils sont intéressants et bien faits mais ne correspondent pas vraiment à mes habitudes :
SpiderFoot est un outil de reconnaissance qui recueille des informations à travers différents modules. Il a une belle interface web et génère des graphiques montrant les liens entre les différents types de données. Ce que je n’aime pas, c’est qu’il est considéré comme l’outil magique qui trouve tout pour vous, mais aucun outil ne pourra jamais vous remplacer pour savoir ce que vous cherchez et analyser les résultats. Oui, vous devrez faire la recherche par vous-même et lire les résultats un par un, et SpiderFoot n’aide pas beaucoup sur ce point. Bon travail et belle interface par contre.
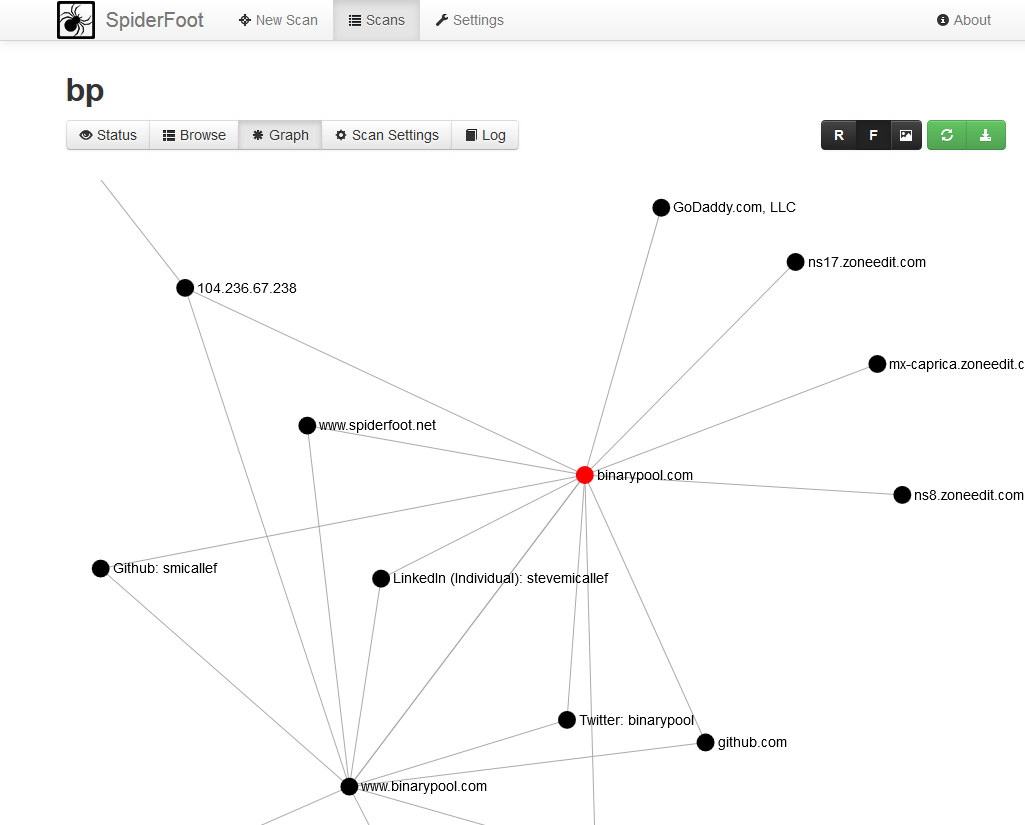
Capture d’écran de SpiderFoot (source : spiderfoot.net)
recon-ng est un bel outil en ligne de commande pour interroger différentes plateformes, réseaux sociaux ou plateformes de threat intel. C’est assez proche de ce que Harpoon fait, en fait. Je ne l’utilise pas parce que j’utilise déjà Harpoon qui correspond à mes besoins et je n’aime pas vraiment l’interface shell qu’il offre.
Buscador est une machine virtuelle Linux qui intègre de nombreux outils OSINT différents. Je préfère toujours avoir mes propres systèmes personnalisés mais c’est une belle façon d’essayer de nouveaux outils sans avoir à les installer un par un.
Allons-y !
Passons maintenant au vrai sujet : qu’est-ce qui peut vous aider dans les enquêtes OSINT ?
Infrastructure technique
L’analyse de l’infrastructure technique est à la croisée des chemins entre le threat intel et le renseignement en source ouverte (OSINT), mais elle constitue certainement une partie importante des enquêtes dans certains contextes.
Voici ce que vous devriez rechercher :
- IP et domaines : il existe de nombreux outils différents pour cela mais je trouve que Passive Total (maintenant appelée RiskIQ) est l’une des meilleures sources d’information. L’accès gratuit vous donne 15 requêtes par jour via l’interface web et 15 via l’API. Je m’y fie beaucoup, mais Robtex, HackerTarget et Security Trails sont d’autres bonnes options.
- Certificats : Censys est un excellent outil, mais crt.sh, moins connu et moins fantaisiste, est aussi une très bonne base de données de transparence des certificats.
- Scans : il est souvent utile de savoir quels types de services s’exécutent sur une IP, vous pouvez faire le scan vous-même avec nmap, mais vous pouvez aussi vous fier à des plateformes qui scannent régulièrement toutes les adresses IPv4 pour vous. Les deux principales plates-formes sont Censys et Shodan, elles se concentrent toutes les deux sur des aspects différents (plus d’IoT pour Shodan, plus sur le TLS pour Censys) donc il est bon de connaître et d’utiliser les deux.
- BinaryEdge est une alternative assez nouvelle mais qui évolue rapidement. Plus récemment, une plateforme chinoise similaire, appelée Fofa, a été lancée. Une autre source d’information est Rapid7 Open Data mais vous devrez télécharger les fichiers de scan et faire vos propres recherches. Enfin, je trouve que les informations historiques sur les adresses IP sont une mine d’or pour comprendre l’évolution d’une plateforme, Censys ne fournit ces données que par le biais d’abonnements payants (disponibles gratuitement pour les chercheurs universitaires) mais Shodan les fournit directement via l’IP, ce qui est formidable ! Regardez la commande harpoon shodan ip ip -H IP pour voir ce qu’elle donne (vous devrez acheter à Shodan un compte à vie).
- Informations sur les menaces : même si elles ne sont pas essentielles dans l’OSINT, il est toujours intéressant de vérifier les activités malveillantes d’un domaine, IP ou URL. Pour ce faire, je m’appuie principalement sur Passive Total et sur AlienVault OTX.
- Sous-domaines : il existe de nombreuses façons de trouver une liste de sous-domaines pour un domaine, de la recherche Google (site:DOMAINE) à la recherche d’autres domaines dans les certificats. PassiveTotal et BinaryEdge implémentent cette fonctionnalité directement, vous pouvez donc simplement les interroger pour obtenir une première liste.
- Google Analytics et les réseaux sociaux : la dernière information qui est vraiment intéressante, est de vérifier si le même ID Google Analytics / Adsense est utilisé dans plusieurs sites web. Cette technique a été découverte en 2015 et est bien décrite ici par Bellingcat. Pour rechercher ces connexions, j’utilise surtout Passive Total, SpyOnWeb et NerdyData (publicwww est une autre alternative non libre).
Moteurs de recherche
Selon le contexte, vous voudrez peut-être utiliser un moteur de recherche différent au cours d’une enquête. Je compte surtout sur Google et Bing (pour l’Europe ou l’Amérique du Nord), Baidu (pour l’Asie) et Yandex (pour la Russie et l’Europe orientale).
Bien sûr, le premier outil d’enquête est l’opérateur de recherche. Vous trouverez une liste complète de ces opérateurs pour Google ici, voici un extrait des plus intéressants :
- Vous pouvez utiliser les opérateurs logiques booléens suivants pour combiner les requêtes : AND, OR, + et –
- filetype: permet de rechercher des extensions de fichiers spécifiques
- site: va filtrer les recherches sur un site web spécifique
- intitle: et inurl: va filtrer sur le titre ou l’url
- link: trouve les pages web ayant un lien vers une url spécifique (obsolète en 2017, mais encore partiellement fonctionnel)
Quelques exemples :
- NOM + CV + filetype:pdf peut vous aider à trouver le CV de quelqu’un
- DOMAINE -site:DOMAINE peut vous aider à trouver les sous-domaines d’un site web
- PHRASE -site:DOMAINEDORIGIN.COM peut vous aider à trouver un site Web qui a plagié ou copié un article
Lectures supplémentaires :
Images
Pour les images, il y a deux choses que vous voulez savoir : comment trouver des informations supplémentaires sur une image et comment trouver des images similaires.
Pour trouver des informations supplémentaires, la première étape consiste à examiner les données Exif. Les données Exif sont des données incorporées dans une image lors de sa création et contiennent souvent des informations intéressantes sur la date de création, l’appareil photo utilisé, parfois des données GPS, etc. Pour le vérifier, j’aime bien utiliser la ligne de commande ExifTool mais l’extension Exif Viewer (pour Chrome et Firefox) est aussi très pratique. De plus, vous pouvez utiliser ce super site Web Photo Forensic qui a beaucoup de fonctionnalités intéressantes (d’autres alternatives sont exif.regex.info et Foto Forensics).
Pour trouver des images similaires, vous pouvez utiliser Google Images, Bing Images, Yandex Images ou TinEye. TinEye a une API utile (voir ici comment l’utiliser) et Bing a une fonctionnalité très utile qui vous permet de rechercher une partie spécifique d’une image. Pour obtenir de meilleurs résultats, il peut être utile de supprimer l’arrière-plan de l’image, remove.bg est un outil intéressant pour cela.
Il n’y a pas de moyen facile d’analyser le contenu d’une image et de trouver son emplacement par exemple. Vous devrez rechercher des éléments spécifiques dans l’image qui vous permettent de deviner dans quel pays elle peut se trouver, puis faire des recherches en ligne et comparer avec des images satellites. Je vous suggère de lire quelques bonnes enquêtes de Bellingcat pour en savoir plus à ce sujet, comme celle-ci ou celle-là.
Lectures supplémentaires :
- Métadonnées : MetaUseful & MetaCreepy par Bellingcat
- Le Guide de vérification visuelle par First Draft news
Réseaux sociaux
Pour les réseaux sociaux, il existe de nombreux outils disponibles, mais ils dépendent fortement de la plateforme. Voici un bref extrait d’outils et d’astuces intéressants :
- Twitter : l’API vous donne le temps exact de création et l’outil utilisé pour publier des tweets. Tweets_analyzer de x0rz est un excellent moyen d’avoir un aperçu de l’activité d’un compte. Il existe des moyens de trouver un identifiant Twitter à partir d’une adresse e-mail, mais ils sont un peu délicats.
- Facebook : la meilleure ressource pour les enquêtes sur Facebook est le site Web de Michael Bazzell, en particulier la page de son outil pour Facebook.
- LinkedIn : le truc le plus utile que j’ai trouvé dans LinkedIn est comment trouver un profil LinkedIn à partir d’une adresse email.
Plateformes de cache
Il existe plusieurs plateformes de mise en cache de sites Web qui peuvent être une excellente source d’information au cours d’une enquête, soit parce qu’un site Web est en panne, soit pour analyser l’évolution historique du site. Ces plates-formes font soit de la mise en cache automatique des sites Web, soit de la mise en cache sur demande.
- Moteurs de recherche : la plupart des moteurs de recherche mettent en cache le contenu des sites Web lorsqu’ils les parcourent. C’est vraiment utile et de nombreux sites Web sont disponibles de cette façon, mais gardez à l’esprit que vous ne pouvez pas contrôler quand il a été mis en cache en dernier (très souvent moins d’une semaine auparavant) et il sera probablement supprimé bientôt, donc si vous y trouvez quelque chose d’intéressant, pensez à sauvegarder rapidement la page mise en cache. J’utilise le cache des moteurs de recherche suivants dans mes enquêtes : Google, Yandex et Bing
- Internet Archive : l’Internet Archive est un grand projet qui vise à sauvegarder tout ce qui est publié sur Internet, ce qui inclut l’exploration automatique des pages Web et la sauvegarde de leur évolution dans une énorme base de données. Ils offrent un portail web appelé Internet Archive Wayback Machine, qui est une ressource incroyable pour analyser les évolutions d’un site web. Une chose importante à savoir est que l’Internet Archive supprime du contenu sur demande (ils l’ont fait par exemple pour la société Stalkerware Flexispy), vous devez donc enregistrer le contenu qui doit être archivé ailleurs.
- Autres plateformes de mise en cache manuelle : J’aime beaucoup archive.today qui permet de sauvegarder des instantanés de pages web et de chercher des instantanés faits par d’autres personnes. perma.cc est bon mais n’offre que 10 liens par mois pour des comptes gratuits, la plateforme est principalement dédiée aux bibliothèques et universités. Leur code est open-source par contre, donc si je devais héberger ma propre plateforme de mise en cache, j’envisagerais certainement d’utiliser ce logiciel.
Parfois, il est ennuyeux d’interroger manuellement toutes ces plateformes pour vérifier si une page Web a été mise en cache ou non. J’ai implémenté une simple commande dans Harpoon pour faire cela :
$ harpoon cache https://citizenlab.ca/2016/11/parliament-keyboy/
Google: FOUND https://webcache.googleusercontent.com/search?q=cache%3Ahttps%3A%2F%2Fcitizenlab.ca%2F2016%2F11%2Fparliament-keyboy%2F&num=1&strip=0&vwsrc=1
Yandex: NOT FOUND
Archive.is: TIME OUT
Archive.org: FOUND
-2018-12-02 14:07:26: http://web.archive.org/web/20181202140726/https://citizenlab.ca/2016/11/parliament-keyboy/
Bing: NOT FOUNDDe plus, gardez à l’esprit que Hunchly, mentionné précédemment, enregistre automatiquement une archive locale de toutes les pages que vous visitez lorsque l’enregistrement est activé.
Collecte des preuves
La collecte de preuves est un élément clé de toute enquête, surtout si elle risque d’être longue. Vous serez certainement perdu-e dans la quantité de données que vous avez trouvées plusieurs fois, les pages web changeront, les comptes Twitter disparaîtront, etc.

Choses à garder à l’esprit :
- Vous ne pouvez pas vous fier à l’Internet Archive, utiliser d’autres plateformes de cache et si possible des copies locales.
- Enregistrer des images, des documents, etc.
- Prendre des captures d’écran
- Sauvegardez les données des comptes de réseaux sociaux, elles peuvent être supprimées à tout moment. (Pour les comptes Twitter, Harpoon a une commande pour sauvegarder les tweets et les infos utilisateur dans un fichier JSON)
Lectures supplémentaires :
- Comment archiver des documents Open Source par Aric Toler de Bellingcat
Raccourcisseurs d’URL
Les raccourcisseurs d’URL peuvent fournir des informations très intéressantes lorsqu’ils sont utilisés, voici un résumé sur la façon de trouver des informations statistiques pour différents fournisseurs :
- bit.ly : ajoutez un + à la fin de l’url, comme ça : https://bitly.com/aa++
- goo.gl : (bientôt obsolète), ajoutez un + à la fin qui vous redirige vers une url comme ça : https://goo.gl/#analytics/goo.gl/[ID HERE]/all_time
- ow.ly est le raccourcisseur d’url de hootsuite mais vous ne pouvez pas voir les statistiques
- tinyurl.com ne montre pas les statistiques mais vous pouvez voir l’url avec http://preview.tinyurl.com/[id]
- Avec tiny.cc, vous pouvez voir les statistiques en ajoutant un ~, comme ça : https://tiny.cc/06gkny~
- Avec bit.do vous pouvez ajouter un – à la fin, comme ça : http://bit.do/dSytb- (les statistiques peuvent être privées)
- adf.ly propose de gagner de l’argent en affichant des annonces lors de la redirection vers le lien. Ils utilisent beaucoup d’autres sous-domaines comme j.gs ou q.gs et ne montrent pas les statistiques publiques.
- tickurl.com : Accédez aux statistiques avec + comme ça : https://tickurl.com/i9zkh+
Certains raccourcisseurs d’url utilisent des ID qui s’incrémentent, dans ce cas il est possible de les énumérer afin de trouver des urls similaires créées à peu près au même moment. Consultez ce bon rapport pour voir un exemple de cette idée.
Renseignements d’entreprise
Plusieurs bases de données sont disponibles pour rechercher des informations sur une entreprise. Les principales sont la base de données Open Corporates et la base de données OCCRP sur les leaks et les documents publics. Pour le reste, vous devrez vous appuyer sur des bases de données par pays, en France societe.com est un bon site, aux Etats-Unis vous devriez consulter EDGAR et au Royaume-Uni, Company House (plus d’informations à ce sujet ici).
Ressources
Voici quelques ressources intéressantes pour en savoir plus sur l’OSINT :
- Les ressources géniales de Bellingcat : les guides et la communauté ont dressé une liste de ressources.
- Le référentiel Github : Awesome OSINT
- Le framework OSINT
- osint.link
C’est tout, merci d’avoir pris le temps de lire ce billet. N’hésitez pas à m’aider à compléter cette liste en me contactant sur Twitter.
Ce billet de blog a été écrit principalement en écoutant du Nils Frahm.
Mise à jour 1 : Ajouté Yandex Images, remove Background et Photo Forensic. Merci à Jean-Marc Manach et fo0 pour leurs conseils.
C’est vraiment un excellent article et les informations et tactiques que vous avez fournies sont très utiles. Merci pour l’article. Il y a un site que j’utilise aussi, vous pouvez l’ajouter si vous le souhaitez. Je vous laisse le soin de regarder. https://securityforeveryone.com/vulnerability-scanning-tools